





Table of contents
- Supervised Machine Learning:
- Classification in Supervised Machine Learning:
- Example Problem: Iris Flower Classification
- Code Implementation:
- Output:
- Discussion:
- Significance of Classification:
- Regression in Supervised Machine Learning:
- Example Problem: Predicting Vehicle Fuel Efficiency
- Code Implementation:
- Output:
- Discussion:
- Significance of Regression:
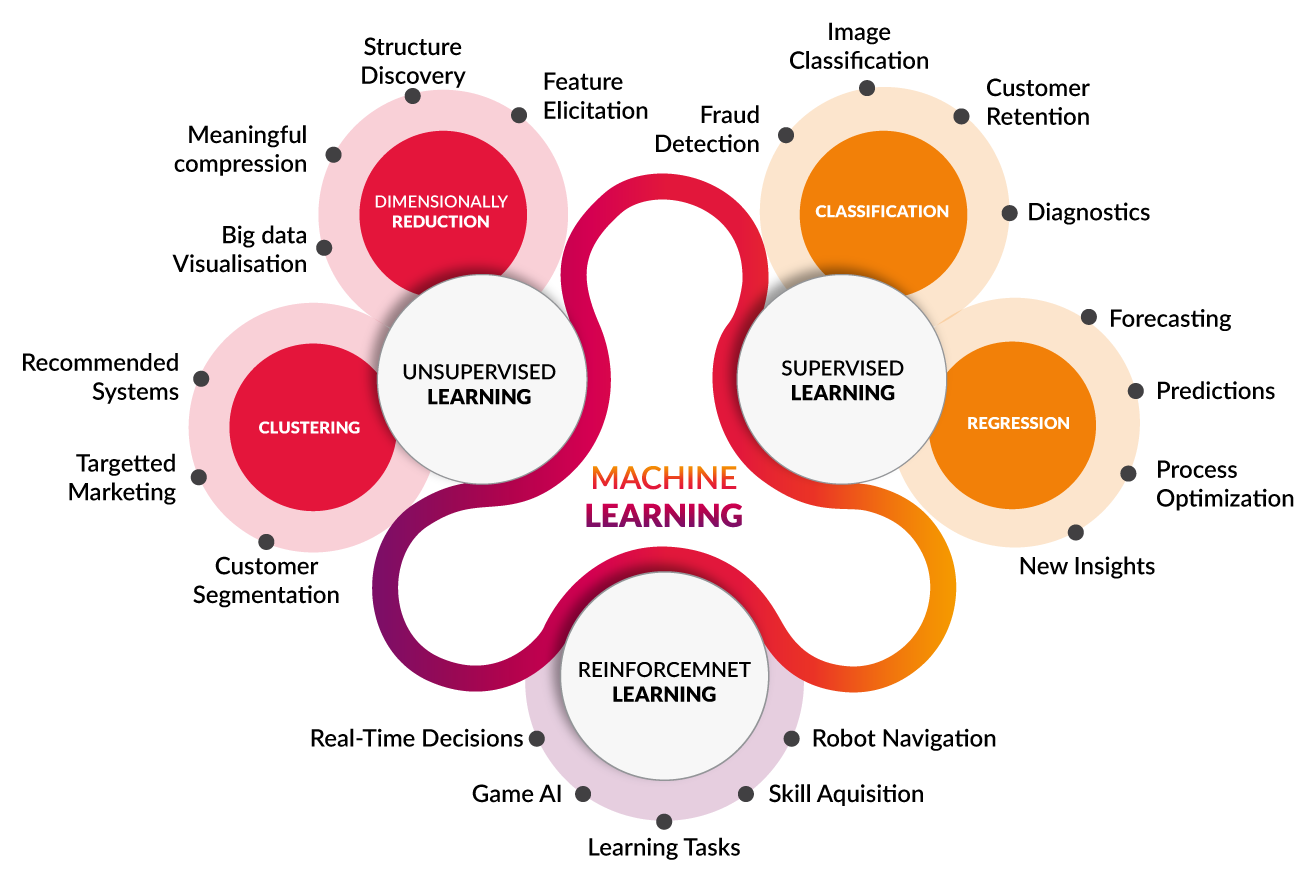
Machine Learning, the transformative force driving innovation in the digital age, can be categorized into three main categories: Supervised Learning, Unsupervised Learning, and Reinforcement Learning.
Supervised Learning: In Supervised Learning, algorithms are trained on labeled data, where each example is paired with its corresponding output. The algorithm learns to map input features to the desired output, making it capable of predicting outcomes for new, unseen data. Supervised Learning excels in tasks like classification and regression, where the algorithm categorizes data or predicts numerical values based on learned patterns.

Unsupervised Learning: Unsupervised Learning involves exploring and analyzing data without explicit guidance or labeled outcomes. Algorithms in this category identify patterns, similarities, and structures within the data, grouping similar data points into clusters or reducing the dimensionality of the dataset. Unsupervised Learning techniques are valuable for tasks like clustering, anomaly detection, and feature extraction, where the goal is to uncover hidden insights and relationships within the data.

Reinforcement Learning: Reinforcement Learning is a paradigm where algorithms learn to make sequential decisions by interacting with an environment to maximize cumulative rewards. Unlike Supervised Learning, Reinforcement Learning agents receive feedback in the form of rewards or penalties based on their actions, guiding them towards optimal strategies. This category is particularly well-suited for tasks involving decision-making in dynamic and uncertain environments, such as game playing, robotics, and autonomous vehicle control.
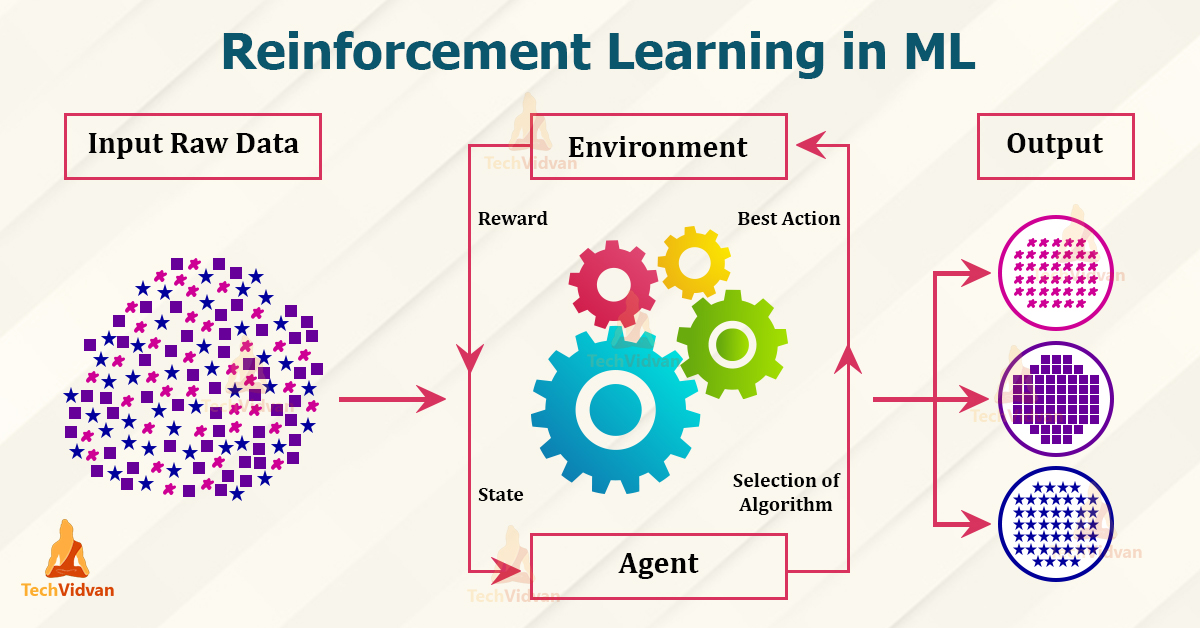
These categories represent the diverse approaches within the field of Machine Learning, each offering unique capabilities and applications. Supervised Learning learns from labeled data to make predictions, Unsupervised Learning uncovers hidden patterns within unlabeled data, and Reinforcement Learning navigates complex environments to optimize decision-making processes. Together, they form the foundation of modern artificial intelligence and drive advancements across various domains, from healthcare and finance to entertainment and beyond.
Supervised Machine Learning:
Supervised Machine Learning stands as a cornerstone in the realm of artificial intelligence, empowering algorithms to learn patterns and relationships from labeled data to make predictions or decisions. Let's delve into the world of Supervised Learning through an example problem: predicting housing prices based on features such as size, number of bedrooms, and location.
It involves training a model on a dataset where each example is accompanied by a target output. The model learns from the input-output pairs to generalize patterns and make predictions on unseen data. In the context of our housing price prediction problem, the dataset contains information about various houses (features) along with their corresponding sale prices (target output).
Supervised Machine Learning encompasses two main types: classification and regression. Classification involves predicting a categorical label or class, while regression predicts a continuous numerical value. Let's explore each type with example problems and code implementations.
Classification in Supervised Machine Learning:
Classification is a fascinating branch of Supervised Machine Learning that deals with the categorization of data into distinct classes or groups based on its features. In classification problems, the goal is to train a model that can accurately assign new, unseen instances to predefined categories. Let's explore the concept of classification through an example problem: the famous Iris flower dataset.
Types of Classification Algorithms:
Logistic Regression:
- Despite its name, Logistic Regression is a classification algorithm used for binary classification problems. It models the probability that an instance belongs to a particular class using the logistic function.
Support Vector Machines (SVM):
- SVM is a powerful classification algorithm that finds the optimal hyperplane that separates different classes in the feature space. It works well for both linear and nonlinear classification problems.
Decision Trees:
- Decision Trees recursively split the feature space into regions based on the values of the input features. They are intuitive and easy to interpret but can be prone to overfitting.
Random Forest:
- Random Forest is an ensemble learning method that builds multiple decision trees and combines their predictions to make more accurate classifications. It is robust to overfitting and noise in the data.
K-Nearest Neighbors (KNN):
- KNN is a simple and intuitive classification algorithm that classifies instances based on the majority class of their nearest neighbors in the feature space. It is non-parametric and does not make assumptions about the underlying data distribution.
Naive Bayes:
- Naive Bayes is a probabilistic classification algorithm based on Bayes' theorem and the assumption of feature independence. It is efficient and works well for text classification and other high-dimensional datasets.
Gradient Boosting Machines (GBM):
- GBM is an ensemble learning technique that builds a sequence of weak learners (typically decision trees) and combines their predictions through gradient descent. It is effective for both regression and classification tasks.
Example Problem: Iris Flower Classification
Dataset Explanation:
The Iris dataset is a classic dataset in Machine Learning, consisting of measurements of sepal length, sepal width, petal length, and petal width for three species of Iris flowers: setosa, versicolor, and virginica. Each species is a distinct class, and the task is to train a model that can classify new iris flowers into one of these three categories.
Sample Table of the Iris Dataset:
| Sepal Length | Sepal Width | Petal Length | Petal Width | Species |
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 5.5 | 2.5 | 4.0 | 1.3 | versicolor |
| ... | ... | ... | ... | ... |
Code Implementation:
Let's use Python and the scikit-learn library to implement a simple classification model using the Iris dataset. We'll employ the Support Vector Machine (SVM) classifier for this task.
# Import necessary libraries
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
from sklearn.datasets import load_iris
# Load the Iris dataset
iris = load_iris()
X = iris.data # Features
y = iris.target # Target output (species)
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the Support Vector Machine (SVM) classifier
model = SVC(kernel='linear', C=1) # Linear SVM with regularization parameter C=1
model.fit(X_train, y_train)
# Make predictions on the test set
y_pred = model.predict(X_test)
# Evaluate the model's accuracy and performance
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print("Accuracy:", accuracy)
print("\nClassification Report:\n", report)
Output:
The output of our code implementation provides us with the accuracy of the model on the test set and a detailed classification report, including precision, recall, and F1-score for each class.

Discussion:
In this classification example using the Iris dataset, we've applied a Support Vector Machine (SVM) classifier to train a model that distinguishes between the three species of Iris flowers. Let's break down our approach:
Data Preparation: We loaded the Iris dataset, which is readily available in scikit-learn. The dataset contains features (sepal length, sepal width, petal length, and petal width) and the target output (species).
Model Training: We split the dataset into training and testing sets, instantiated a linear SVM model, and trained it on the training data using the
fitmethod.Model Evaluation: We made predictions on the test set using the trained model and evaluated its performance. The accuracy score provides an overall measure of the model's correctness, while the classification report offers a more detailed analysis, including precision (accuracy of positive predictions), recall (true positive rate), and F1-score (harmonic mean of precision and recall) for each class.
Significance of Classification:
Classification is a versatile tool with applications across various domains. In healthcare, it aids in disease diagnosis based on patient data. In finance, it helps detect fraudulent transactions. In sentiment analysis, it categorizes text as positive, negative, or neutral. The possibilities are vast, making classification a fundamental technique in Machine Learning.
Regression in Supervised Machine Learning:
Regression is a powerful technique in Supervised Machine Learning that deals with predicting continuous numerical values based on input features. Unlike classification, where the goal is to assign instances to predefined categories, regression focuses on estimating a target output that lies on a continuous scale. Let's explore regression through an example problem: predicting the fuel efficiency of vehicles based on their attributes.
Types of Regression Algorithms:
Linear Regression:
- Linear Regression is a simple and widely used regression algorithm that models the relationship between the independent variables and the dependent variable using a linear equation. It works well for problems where the relationship between the variables is linear.
Polynomial Regression:
- Polynomial Regression extends linear regression by adding polynomial terms to the model equation. It can capture more complex relationships between the variables and is useful when the data exhibits nonlinear patterns.
Ridge Regression:
- Ridge Regression is a regularization technique that adds a penalty term to the cost function to prevent overfitting. It is particularly effective when dealing with multicollinearity in the data.
Lasso Regression:
- Lasso Regression is another regularization technique that penalizes the absolute size of the regression coefficients. It can be useful for feature selection and reducing the complexity of the model.
ElasticNet Regression:
- ElasticNet Regression combines the penalties of Ridge and Lasso regression. It is beneficial when there are multiple features correlated with each other.
Example Problem: Predicting Vehicle Fuel Efficiency
Dataset Explanation:
For our regression example, we'll use the "Auto MPG" dataset, which contains information about various cars, including attributes like cylinders, displacement, horsepower, weight, acceleration, model year, and origin. Our objective is to train a regression model that can predict the miles per gallon (MPG) of vehicles based on these attributes.
Sample Table of the Auto MPG Dataset:
| Cylinders | Displacement | Horsepower | Weight | Acceleration | Model Year | Origin | MPG |
| 8 | 307.0 | 130.0 | 3504 | 12.0 | 70 | 1 | 18.0 |
| 8 | 350.0 | 165.0 | 3693 | 11.5 | 70 | 1 | 15.0 |
| 4 | 108.0 | 93.0 | 2391 | 15.5 | 72 | 3 | 32.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
Code Implementation:
Let's implement a simple regression model using Python and the scikit-learn library to predict the MPG of vehicles based on their attributes.
# Import necessary libraries
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_boston
# Load the Auto MPG dataset
auto_mpg = load_boston()
X = auto_mpg.data # Features
y = auto_mpg.target # Target output (MPG)
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the Linear Regression model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions on the test set
y_pred = model.predict(X_test)
# Evaluate the model using Mean Squared Error (MSE)
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
Output:
The output of our code implementation provides us with the Mean Squared Error (MSE), a metric used to evaluate the performance of regression models. A lower MSE indicates better predictive accuracy.

Discussion:
In our regression example using the Auto MPG dataset, we utilized Supervised Learning techniques to train a Linear Regression model that predicts the fuel efficiency of vehicles based on attributes like cylinders, displacement, horsepower, weight, and more. Here's a breakdown of our approach:
Data Preparation: We loaded the Auto MPG dataset, which contains features (X) and the corresponding target output (y). The features represent various attributes of vehicles, while the target output is the miles per gallon (MPG).
Model Training: We split the dataset into training and testing sets using the
train_test_splitfunction from scikit-learn. We then instantiated a Linear Regression model and trained it on the training data using thefitmethod.Model Evaluation: We made predictions on the test set using the trained model and evaluated its performance using the Mean Squared Error (MSE) metric. MSE measures the average squared difference between the predicted and actual values. A lower MSE indicates that the model's predictions are closer to the actual values.
Significance of Regression:
Regression finds applications in a wide range of fields, including finance, economics, healthcare, and environmental science. In finance, regression models can predict stock prices and analyze market trends. In healthcare, they can estimate patient outcomes based on medical data. In environmental science, they can forecast climate patterns and analyze environmental factors.
In conclusion, supervised machine learning algorithms represent a powerful toolkit for solving a wide range of real-world problems in both regression and classification tasks. Through the exploration of regression algorithms like Linear Regression, Polynomial Regression, and regularization techniques like Ridge, Lasso, and ElasticNet, we can predict continuous numerical values with remarkable accuracy, paving the way for informed decision-making in various domains.
Similarly, in the realm of classification, algorithms such as Logistic Regression, Support Vector Machines (SVM), Decision Trees, Random Forests, K-Nearest Neighbors (KNN), Naive Bayes, and Gradient Boosting Machines (GBM) empower us to categorize data into distinct classes, enabling applications across finance, healthcare, marketing, and more.
As we continue to unlock the potential of machine learning, it's essential to understand the strengths and weaknesses of each algorithm and select the most appropriate one based on the problem at hand, the nature of the data, and the desired outcome. Moreover, the iterative process of model training, evaluation, and refinement is crucial for building robust and accurate machine learning models that generalize well to unseen data.
In the dynamic landscape of artificial intelligence, supervised machine learning algorithms serve as invaluable tools for extracting insights from data, uncovering patterns, making predictions, and driving innovation and progress in diverse fields. As technology advances and datasets grow in complexity, the evolution and refinement of supervised learning techniques will continue to shape the future of AI, offering solutions to increasingly complex challenges and unlocking new frontiers of knowledge and discovery.
